Knowledge Distillation for Convolution Neural Networks using Pytorch

What exactly is “Knowledge Distillation”?
Neural Networks have proven to be a good way of learning various tasks in recent times. However, these neural networks are growing deeper and deeper, with the number of parameters increasing to millions and sometimes billions, which limits the use of these networks to just high computational devices. With the rise in smart mobile devices like smartwatches, augmented reality glasses, and various other devices, the current need of the hour is to have networks with a smaller number of parameters. Knowledge Distillation is one such technique to transfer the knowledge of big pre-trained models like ResNet, VGG, etc. to smaller networks. An “obvious” way, as mentioned in the paper Distilling the Knowledge in a Neural Network by Geoffrey Hinton 2015[1], to transfer the knowledge from a teacher model to a student model is by using “soft targets” for the training process of the student model. OK, I am convinced about its use, but how exactly is it done?
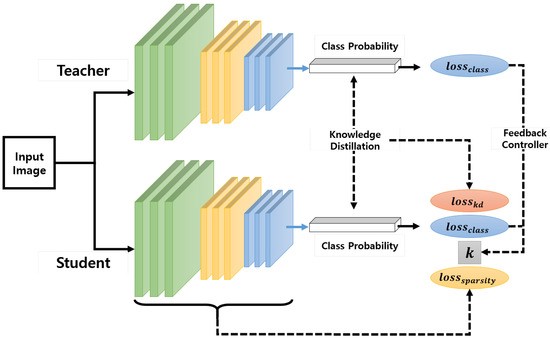 |
|---|
| Overview of the teacher-student model [2] |
As you can see in the above figure, the loss function uses KL Divergence of the teacher and student’s class probabilities and the loss from the actual labels. Now let’s take a look at the loss function for knowledge distillation.

Let’s break this down. m is the batch size. Dₖₗ is the KL Divergence between the outputs of P (the “soft labels” from the teacher network) and Q (the softmax scores from the student network). T here is the temperature to soften the probability distribution; α is the relative importance of the teacher’s guidance to be provided while training w.r.t hard targets from data[1].
Enough of the theory, let’s look at some code.
Let’s get started with some basic stuff. Importing necessary libraries
import time
import copy
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torchvision
from torchvision import datasets, transforms
from torchsummary import summary
from torch.optim import lr_scheduler
import torch.nn.functional as F
import torch.nn as nn
import torchvision.models as models
from torch import nn, optim
Now let us import the dataset. I am using the CIFAR10 dataset. You can try knowledge distillation using any dataset. I am resizing the image to (224,224) because the pre-trained model, Resnet, was trained on ImageNet, which had an image size of (224,224).
transform = transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,
0.406], [0.229, 0.224, 0.225])])
trainset = datasets.CIFAR10(‘/content/train/’, download=True, train=True, transform=transform)
valset = datasets.CIFAR10(‘/content/val/’, download=True, train=False, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
valloader = torch.utils.data.DataLoader(valset, batch_size=64, shuffle=True)
len_trainset = len(trainset)
len_valset = len(valset)
classes = (‘plane’, ‘car’, ‘bird’, ‘cat’,‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’)
device = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)
As a sanity check the shape of the images and the labels
dataiter = iter(trainloader)
images, labels = dataiter.next()
print(images.shape)
print(labels.shape)
Now, Let’s define the teacher network, i.e., ResNet50, and freeze its inner layers.
resnet = models.resnet50(pretrained=True)
for param in resnet.parameters():
param.requires_grad = False
num_ftrs = resnet.fc.in_features
resnet.fc = nn.Linear(num_ftrs, 10)
resnet = resnet.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(resnet.fc.parameters())
Great! Let’s train this pre-trained model.
def train_and_evaluate(model, trainloader, valloader, criterion, optimizer, len_trainset, len_valset, num_epochs=25):
model.train()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
model.train()
print(‘Epoch {}/{}’.format(epoch, num_epochs — 1))
print(‘-’ * 10)
running_loss = 0.0
running_corrects = 0
for inputs, labels in trainloader:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len_trainset
epoch_acc = running_corrects.double() / len_trainset
print(‘ Train Loss: {:.4f} Acc: {:.4f}’.format(epoch_loss,
epoch_acc))
model.eval()
running_loss_val = 0.0
running_corrects_val = 0
for inputs, labels in valloader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs,labels)
_, preds = torch.max(outputs, 1)
running_loss_val += loss.item() * inputs.size(0)
running_corrects_val += torch.sum(preds == labels.data)
epoch_loss_val = running_loss_val / len_valset
epoch_acc_val = running_corrects_val.double() / len_valset
if epoch_acc_val > best_acc:
best_acc = epoch_acc_val
best_model_wts = copy.deepcopy(model.state_dict())
print(‘ Val Loss: {:.4f} Acc: {:.4f}’.format(epoch_loss_val,
epoch_acc_val))
print()
print(‘Best val Acc: {:4f}’.format(best_acc))
model.load_state_dict(best_model_wts)
return model
Now run the function to train the ResNet.
resnet_teacher = train_and_evaluate(resnet,trainloader,
valloader,criterion,optimizer_ft,
len_trainset,len_valset,10)
GREAT! Half of our job’s done. Now, let us move on and define our student network, that is going to learn from the teacher network we just trained.
class Net(nn.Module):
“””
This will be your student network that will learn from the
teacher network in our case resnet50.
“””
def __init__(self):
super(Net, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size = (3,3), stride = (1,1),
padding = (1,1)),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size = (3,3), stride = (1,1),
padding = (1,1)),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0,
dilation=1, ceil_mode=False)
)
self.layer2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size = (3,3), stride = (1,1),
padding = (1,1)),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size = (3,3), stride = (1,1),
padding = (1,1)),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0,
dilation=1, ceil_mode=False)
)
self.pool1 = nn.AdaptiveAvgPool2d(output_size=(1,1))
self.fc1 = nn.Linear(128, 32)
self.fc2 = nn.Linear(32, 10)
self.dropout_rate = 0.5
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.pool1(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.fc2(x)
return x
net = Net().to(device)
Again a sanity check for the output of the network.
dataiter = iter(trainloader)
images, labels = dataiter.next()
out = net(images.cuda())
print(out.shape)
OK! Let’s define the loss function that I described in the beginning and a helper function.
def loss_kd(outputs, labels, teacher_outputs, temparature, alpha):
KD_loss = nn.KLDivLoss()(F.log_softmax(outputs/temparature,
dim=1),F.softmax(teacher_outputs/temparature,dim=1)) *
(alpha * temparature * temparature) +
F.cross_entropy(outputs, labels) * (1. — alpha)
return KD_loss
def get_outputs(model, dataloader):
'''
Used to get the output of the teacher network
'''
outputs = []
for inputs, labels in dataloader:
inputs_batch, labels_batch = inputs.cuda(), labels.cuda()
output_batch = model(inputs_batch).data.cpu().numpy()
outputs.append(output_batch)
return outputs
Now, coming to the main training loops of the whole thing.
def train_kd(model,teacher_out, optimizer, loss_kd, dataloader, temparature, alpha):
model.train()
running_loss = 0.0
running_corrects = 0
for i,(images, labels) in enumerate(dataloader):
inputs = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
outputs_teacher = torch.from_numpy(teacher_out[i]).to(device)
loss = loss_kd(outputs,labels,outputs_teacher,temparature,
alpha)
_, preds = torch.max(outputs, 1)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(trainset)
epoch_acc = running_corrects.double() / len(trainset)
print(‘ Train Loss: {:.4f} Acc: {:.4f}’.format(epoch_loss,
epoch_acc))
def eval_kd(model,teacher_out, optimizer, loss_kd, dataloader, temparature, alpha):
model.eval()
running_loss = 0.0
running_corrects = 0
for i,(images, labels) in enumerate(dataloader):
inputs = images.to(device)
labels = labels.to(device)
outputs = model(inputs)
outputs_teacher = torch.from_numpy(teacher_out[i]).cuda()
loss = loss_kd(outputs,labels,outputs_teacher,temparature,
alpha)
_, preds = torch.max(outputs, 1)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(valset)
epoch_acc = running_corrects.double() / len(valset)
print(‘ Val Loss: {:.4f} Acc: {:.4f}’.format(epoch_loss,
epoch_acc))
return epoch_acc
def train_and_evaluate_kd(model, teacher_model, optimizer, loss_kd, trainloader, valloader, temparature, alpha, num_epochs=25):
teacher_model.eval()
best_model_wts = copy.deepcopy(model.state_dict())
outputs_teacher_train = get_outputs(teacher_model, trainloader)
outputs_teacher_val = get_outputs(teacher_model, valloader)
print(“Teacher’s outputs are computed now starting the training
process-”)
best_acc = 0.0
for epoch in range(num_epochs):
print(‘Epoch {}/{}’.format(epoch, num_epochs — 1))
print(‘-’ * 10)
# Training the student with the soft labes as the outputs
from the teacher and using the loss_kd function
train_kd(model, outputs_teacher_train,
optim.Adam(net.parameters()),loss_kd,trainloader,
temparature, alpha)
# Evaluating the student network
epoch_acc_val = eval_kd(model, outputs_teacher_val,
optim.Adam(net.parameters()), loss_kd,
valloader, temparature, alpha)
if epoch_acc_val > best_acc:
best_acc = epoch_acc_val
best_model_wts = copy.deepcopy(model.state_dict())
print(‘Best val Acc: {:4f}’.format(best_acc))
model.load_state_dict(best_model_wts)
return model
Voila!!!! You are done. The last thing to do is just run the function to train your student network. :)
stud=train_and_evaluate_kd(net,resnet_teacher, optim.Adam(net.parameters()),loss_kd,trainloader,valloader,1,0.5,20)
PS: I have set the temperature to 1 and alpha to 0.5. These are hyper-parameters that you can tune.
That concludes this article on Knowledge Distillation for Convolutional Networks. Hope you liked what you just read, and thank you for your time.
✌️
References
[1] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. “Distilling the knowledge in a neural network.” arXiv:1503.02531 (2015).
[2] Cho, Jungchan, and Lee, Minsik. “Building a Compact Convolutional Neural Network for Embedded Intelligent Sensor Systems Using Group Sparsity and Knowledge Distillation” https://doi.org/10.3390/s19194307 (2019)